
티스토리 뷰

Issue
요즘 갓생이란 단어가 매우 유행이다.
갓생이란 간단히 말해서 부지런한 삶을 사는 것을 의미하는데, 나 또한 이 갓생을 한 번 살아보기 위해 친구들과 매일 퇴근 후, 캠스터디를 하는 중이다.
🔽 캠스터디가 무엇인지 궁금하다면 아래 더보기를 눌러보자!
캠스터디란, 서로의 공부하는 모습을 화상으로 공유하여 온라인상에서도 마치 오프라인처럼 면학 분위기를 느낄 수 있는 온라인 스터디 모임을 의미한다 ^,^
그런데 캠스터디 플랫폼으로 디스코드를 선택하고, 약 1주 정도 진행하는 와중... 스터디를 하다 보니 이것저것 필요한 게 꽤 많다는 것을 알게 되었다. 공부 시간 인증이라거나, 무단 불참에 대한 제재 등등..
공부하기도 바빠 죽겠는데 이런 규칙들을 일일이 관리하고, 회원들에게 공지하는 건 너무나 귀찮으면서도 시간을 많이 잡아먹는 일이었다. 마침 디스코드에는 봇이라는 아주 좋은 서비스가 있어 혹시 스터디를 관리해주는 봇이 있나 싶어 찾아보았지만, 역시나 없었다.
그래서 디스코드 봇을 직접 만들어보았다. 이름하여 Time2Study!
Discord Bot - Time2Study
time2study.kro.kr
Time2Study의 기능이나 사용법 등에 대해서는 위 링크를 참고하자.
Development
아무래도 기술 블로그이다 보니, Time2Study의 기술 스택과 개발 과정에 대해서 간단하게 소개해보려 한다.
프로젝트 구성
Time2Study 프로젝트는 크게 두 가지의 프로덕트로 나뉠 수 있다. 하나는 이번 프로젝트에서 가장 중요한 역할을 하는 디스코드 봇인 백엔드 프로덕트이고, 다른 하나는 Time2Study를 소개하는 랜딩 페이지인 프론트엔드 프로덕트이다.
두 프로덕트 모두 Git을 통해 CI/CD를 하였고, 프론트엔드 프로덕트의 경우, 여기에서 소스코드를 확인할 수 있다. 백엔드 프로덕트는 디스코드 봇에 프리미엄 서비스를 넣어볼까 하는 고민도 있어서 소스코드 공개는 하지 않을 예정이다..!
개발 기간
백엔드 프로덕트(디스코드 봇)의 경우, 7월 16일에서 8월 10일까지 약 한 달 정도의 개발 기간이 소요되었고, 그 이후부터는 에러 리포트 등에 대응하면서 유지보수를 하는 중이다.
프론트엔드 프로덕트(랜딩 페이지)의 경우, 디스코드 봇이 완성된 후에 8월 15일부터 8월 18일까지 진행하였다. 아무래도 프로덕트 소개만 하는 웹사이트다 보니 간단해서 개발 기간이 짧았다.
사용 Stack
프론트엔드 프로덕트는 React를 사용하였으며, 백엔드 프로덕트의 경우, 아래 그림에서 볼 수 있듯이 Node js, Postgres DB, discord.js 등을 사용하였다.
참고로 discord.js는 디스코드에서 공식적으로 지원하는 node 패키지가 아니다. 디스코드에서는 개발자들이 디스코드 봇을 개발할 수 있도록 Discord API를 제공하고 있는데, 이를 사용하기 쉽도록 제삼자가 Wrapping 한 것이 discord.js이다. 만약 API 사용에 익숙하지 않고, 본인이 node js를 사용한다면 discord.js를 통해 비교적 쉽고 빠르게 디스코드 봇을 개발할 수 있다.
이외에도 많은 고마운 분들께서 다양한 언어에서 디스코드 봇을 개발할 수 있도록 비공식 라이브러리를 제공하고 있다. 관련 내용은 아래를 참고하자.
| 언어 | 라이브러리 |
| Python | discord.py |
| Java | JDA |
| C# | Discord.net |
| Go | Discordgo |
개발 과정
디스코드 봇을 개발하는 방법에 대해서는 Discord API의 공식 문서와 discord.js의 문서에 설명이 아주 잘 되어 있다. 따라서 이번 섹션은 개발하는 과정에서 부딪혔던 여러 이슈와 그 의사 결정 과정에 할애를 할까 한다.
1. 무료 호스팅? Heroku!
개발 단계에서는 로컬 호스트에 테스트 서버를 올려 Time2Study의 기능을 테스트해왔었는데, 실제 유저에게 지속적인 서비스 제공 및 배포를 하기 위해 서버 호스팅이 필요한 시점이 다가왔다.
AWS를 사용할까 싶었지만, 내 개인 계정은 프리티어가 끝나서 24시 호스팅을 하기 위해서는 요금을 내야 하는 상황이었다. 그래서 무료로 사용할 수 있는 호스팅 업체가 없나 탐색하던 와중, Heroku를 알게 되었다.
Heroku의 무료 플랜을 사용하면 속도가 다소 느리고, 용량이 제한적이라는 한계가 있지만, 내 프로덕트의 경우에는 우수한 성능이 필요하지 않아서 Heroku를 사용하기로 결정하였다. 또한, Github Actions를 통해 배포 파이프라인을 구축하지 않더라도, Heroku에서 특정 브랜치를 기반으로 자동 배포를 지원한다는 점이 마음에 들었다!
따라서 랜딩 페이지도 마찬가지로 Heroku에서 호스팅을 하기로 결정하였고, 내도메인.한국 이라는 곳에서 무료 도메인을 받아 Heroku의 DNS에 연결하였다.
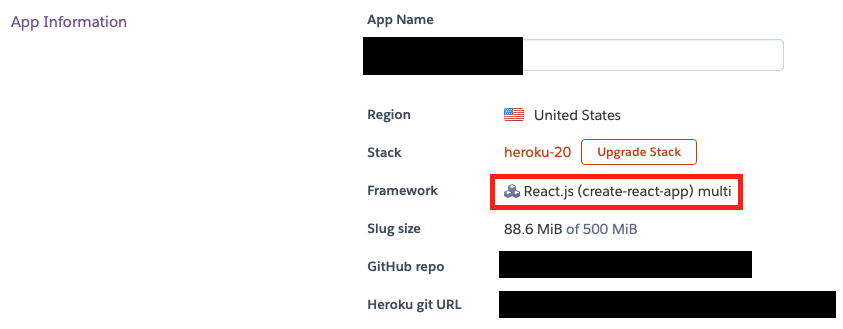
🔽 React 웹사이트를 Heroku에 배포할 시, 실패하는 경우
React 기반 웹사이트를 Heroku에 배포할 때 Framework와 Buildpacks가 아래와 다른 값으로 설정되어 있으면 실패한다. Heroku app의 Framework와 Buildpacks가 아래처럼 설정되어 있는지 확인해보자.

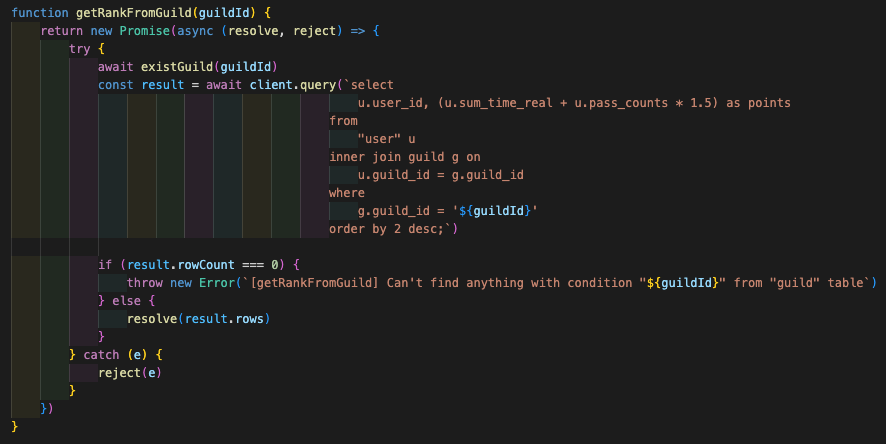
2. File System이 아닌 RDBMS를 활용하자!
Time2Study는 여러 기능을 지원하기 위해 목표 공부 시간, 보유 뱃지 수 등 유저와 관련된 여러 정보를 수집하고 관리한다. 서비스를 운영하기 이전에는 이러한 데이터들을 단순하게 json 파일로 관리하여 File I/O를 통해 데이터를 읽고, 수정하였다.
물론 지금은 사용자 수가 적고, 관련된 정보가 적어 File을 I/O 하는 과정이 짧기에 큰 문제가 되지 않는다. 하지만, 나중에 데이터가 많아지고 복잡한 쿼리가 필요한 경우를 고려했을 때 관계형 데이터베이스로 이전하는 것이 옳다고 생각했다.
그래서 서비스를 운영하기 직전, File System을 버리고 PostgreSQL로 교체하는 작업을 진행했다. 데이터베이스 핸들링을 편하게 하기 위해 node-postgres라는 패키지를 사용하였고, 자주 쓰이는 연속적인 SQL 쿼리들을 기능 단위로 묶어서 API로 만들었다.
RDBMS 작업을 하는 것 자체는 큰 어려움이 없었다. 하지만, 앞으로는 확장성, 편의성 등 다양한 변수들을 기반으로 신중하게 아키텍처를 설계해야겠다는 생각이 들었다. 만약 실제 운영 중에 이러한 문제에 부딪혔다면 상당히 당황스러웠을 듯하다.
DB 서버 또한 디스코드 봇 서버처럼 상시 동작을 해야 하는데, Heroku에서 용량 제한이 있는 무료 PostgreSQL DB 서버를 특정 app에 붙일 수 있다. 이를 사용할 경우, 디스코드 봇 서버에서는 node-postgres 패키지를 통해 아래 사진에 보이는 credential 정보를 인자로 전달하여 client로서 접속하고 CRUD를 수행하면 된다.

const { Client } = require("pg")
const client = new Client({
user: user,
host: db host,
database: db name,
password: db pwd,
port: port,
})
3. Prod 및 Dev 환경으로 분리하자!
서비스를 정식 출시하기 전이라면, 하나의 서버 환경에서 개발하고, 테스트를 하는 것이 큰 문제가 되지 않을 수 있다. 하지만, 이미 정식 운영을 하는 중이라면, 실제 유저들이 사용하는 Prod 서버와 개발 및 검증용 목적인 Dev 서버로 나누는 것이 좋다.
특정 기능을 개발하고, 잘 동작하는지 테스트하기 위해 Prod 서버에 배포하였을 경우, 미처 파악하지 못한 오류가 있어서 시스템이 뻗는다면... 상상만 해도 끔찍하다. 지속 가능한 서비스를 제공하고, 위와 같은 불상사를 막기 위해 Prod 및 Dev 환경으로 서버를 분리하는 것은 정말 중요하다고 생각한다.
이때 환경 분리는 JS의 경우, dot-env 패키지와 package.json의 빌드 스크립트를 통해 쉽게 적용 가능하다.
먼저 .env.dev 및 .env.prod 파일을 생성하고, 이 파일에 서버 Host, DB URL 등 분리가 필요한 환경 변수들의 값을 작성해준다.
// .env.prod
ENV=prod
DATABASE_URL=https://xxxxxx
DISCORD_TOKEN=XXXXXXXXX
다음으로 아래 사진과 같이 dev용, prod용 빌드 스크립트를 나눠 작성하고, 소스 코드에서는 process.env.XX로 환경 변수에 접근하면 된다. (dot-env 패키지는 .env 파일에 작성되어 있는 값을 환경변수로 가져오므로 아래 스크립트처럼 .env.dev 또는 .env.prod를 .env 파일로 복사해주자)
// package.json
"scripts": {
"build:dev": "cp .env.dev .env && node .",
"build:prod": "cp .env.prod .env && node .",
},
한 가지 주의해야 할 것은 환경 변수 특성상, 외부에 노출되어서는 안 될 아주 중요한 정보일 경우가 대다수이므로 만약 github을 통해 CI/CD를 하고 있다면, .gitingore 파일에 환경 변수 관련 파일을 추가하는 것을 잊지 말자.
// .gitignore
node_modules
.env
.env.prod
.env.dev
yarn-error.log
Limits
이렇게 Time2Study의 개발을 완료하였다. 아, 완료는 아니고 세상에 내보낼 준비가 되었다 정도로 해두는 게 좋을 것 같다. 요즘 개발자로서 일을 하며 느낀 생각은 사실 프로덕트에 있어서 완료라는 것은 없다는 것이다. 다양한 이유로 유지보수와 모니터링이 필요한 상황이 찾아오며 이를 통해 SW는 생명을 이어 나간다. SW가 생명을 잃는 순간은 더 이상 유지보수를 이어나갈 의지가 없는 경우인 것 같다.
Time2Study에게는 앞으로 어떠한 상황이 찾아올까? 지금 당장에 생각하더라도 사실 개발 관련 부분에서나, 개발 외적인 부분에서나 정말 많은 개선이 아직 필요하다. 개발 외적인 부분을 고려하는 것은 이번 프로젝트의 목표가 아니었기에 개발 관련 부분에 대해 조금 다루어보자면 다음과 같다.
node-schedule, 너 왜 그래?
Time2Study의 여러 기능 중에 뱃지 시스템이란 기능이 있다. 유저의 다양한 정보를 기반으로 특정 조건을 만족할 경우, 뱃지를 제공하는 시스템인데 그러기 위해서는 특정 시점에 유저의 정보를 수집하고 분석하는 크롤러가 필요하다.
여기서 난관에 부딪혔던 점은 언제, 어디서, 어떻게 정보를 수집할 것이냐였다. 내가 떠올린 방법들은 아래와 같다.
1. 뱃지 관련 유저 정보를 생성하는 모든 소스 코드 위치에 크롤러를 추가한다.
2. 시간 간격이 짧은 스케줄러를 하나 만들고, 여기에 크롤러를 붙여서 비교적 빠른 피드백을 준다.
3. 시간 간격이 긴 스케줄러를 하나 만들고, 여기에 크롤러를 붙여서 피드백은 느리지만, 리소스 소모를 최소한으로 한다.
여기서 1번 방법은 리소스 소모도 적고, 즉각적인 피드백을 기대할 수 있지만 소스 코드 관리 측면에서 불필요한 종속성이 높아지고, 휴먼 에러가 발생할 가능성도 높다고 판단해서 진행하지 않았다.
2번 방법은 비교적 피드백이 빠르겠지만 유저 경험 측면에서는 3번 방법과 차이 없을 것이라 생각하였고, 그럼에도 불구하고 리소스 소모가 많다는 점에서 진행할 가치가 적다고 생각하였다.
이러한 이유로 3번 방법을 선택하였고, node-schedule을 통해 스케줄러를 만들었는데... 우선 크롤링 방법도 마음에 들지 않지만, 그것보다 더 문제인 것은 node-schedule이 어떨 때는 정상적으로 동작하고 어떨 때는 동작하지 않는다는 점이다. 버그 재현이 어려워서 아직 원인 파악 및 해결 방법을 찾지 못하는 중이다.
뱃지 시스템을 비롯한 Time2Study에서 스케줄링을 필요로 하는 다양한 기능들에서 node-schedule을 사용 중이라서 여기에 대해 시간을 들여 개선할 필요가 있다고 생각한다.
미래에는 로드 밸런싱이 필요할 수도 있어!
지금은 유저 수가 현저히 적기 때문에 (앞으로도 그럴 가능성이 매우 크기 때문에) 로드 밸런싱을 고려하지 않고, 하나의 프로세스에서 모든 request 들을 순차적으로 처리하고 있다. 하지만 앞으로 유저 수가 더 늘어날 수도 있으며, 그렇지 않다 하더라도 무중단 배포 등 다양한 상황에서 필요할 수 있기에 로드 밸런싱 작업을 고려하는 것이 좋다고 생각한다.
그렇다면 디스코드 봇 서버에는 로드 밸런싱을 어떻게 적용할 수 있을까?
우선 Heroku를 사용하는 경우라면, 단순히 웹 컨테이너 역할을 하는 dyno의 수를 늘려주고, pm2를 사용하여 cpu 개수만큼 디스코드 봇 서버 프로세스를 할당하면 된다. 하지만 단순히 하나의 동일한 디스코드 봇 서버 프로세스를 여러 개 실행하는 경우, 디스코드 서버로부터 오는 메시지에 대해 모든 프로세스들이 응답을 하기 때문에 사용자가 여러 개의 응답을 받는 경우가 발생하게 된다.
따라서 이 방법을 사용할 경우, 디스코드 봇 서버를 기능 단위로 몇몇의 프로세스로 쪼갠 다음, 디스코드 API 중 Shard라는 기능을 활용해 각각의 프로세스들이 특정 메시지만 처리하도록 해야 한다. 이렇게 하면 메시지의 종류에 따라 이를 적절히 분산하여 처리한다는 점에서 한 개의 프로세스에서 모든 것을 처리할 때 보다 성능이 좋아진다는 장점이 있다.
그런데 막상 이렇게 구상하고 보니, 하나의 프로세스를 여러 개의 작은 단위로 쪼갠다는 점에서 MSA와 매우 흡사하다는 것을 알게 되었다. 어차피 dyno의 개수를 늘리면 더 이상 Heroku를 무료로 사용하지도 못하는데... MSA는 실제 사용량에 대해서만 요금을 부과한다는 비용적인 측면에서 이를 사용하지 않을 이유가 없는 듯하다.
위와 같은 관점에서 보았을 때 추후에 AWS로 서비스를 이관할 필요가 있다고 생각한다.
'🖥 프로젝트' 카테고리의 다른 글
| 백엔드 프레임워크를 직접 구현해보자! - Flint (Numble Node.js 챌린지 X Chekit) (0) | 2022.09.15 |
|---|
- Total
- Today
- Yesterday
- 딥러닝 엔지니어
- mmc_spi
- Cortex-M0
- CNN
- Shortcut
- Cortex 시리즈
- 그래프
- 깊이우선탐색
- 머신러닝
- 그래프탐색
- 알고리즘
- TensorFlow Developer Certificate
- ARM Cortex-M3 시스템 프로그래밍 완전정복1
- Cortex-M3
- 강의제안
- ARM 역사
- BFS
- 너비우선탐색
- 백준
- DFS
- 딥러닝
- 텐서플로우 자격증
- 머신러닝 엔지니어
- 코딩테스트
- SQL 완주반
- ResNet
- 구글 머신러닝 부트캠프
- 완주반
- 패스트캠퍼스
- spidev
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |